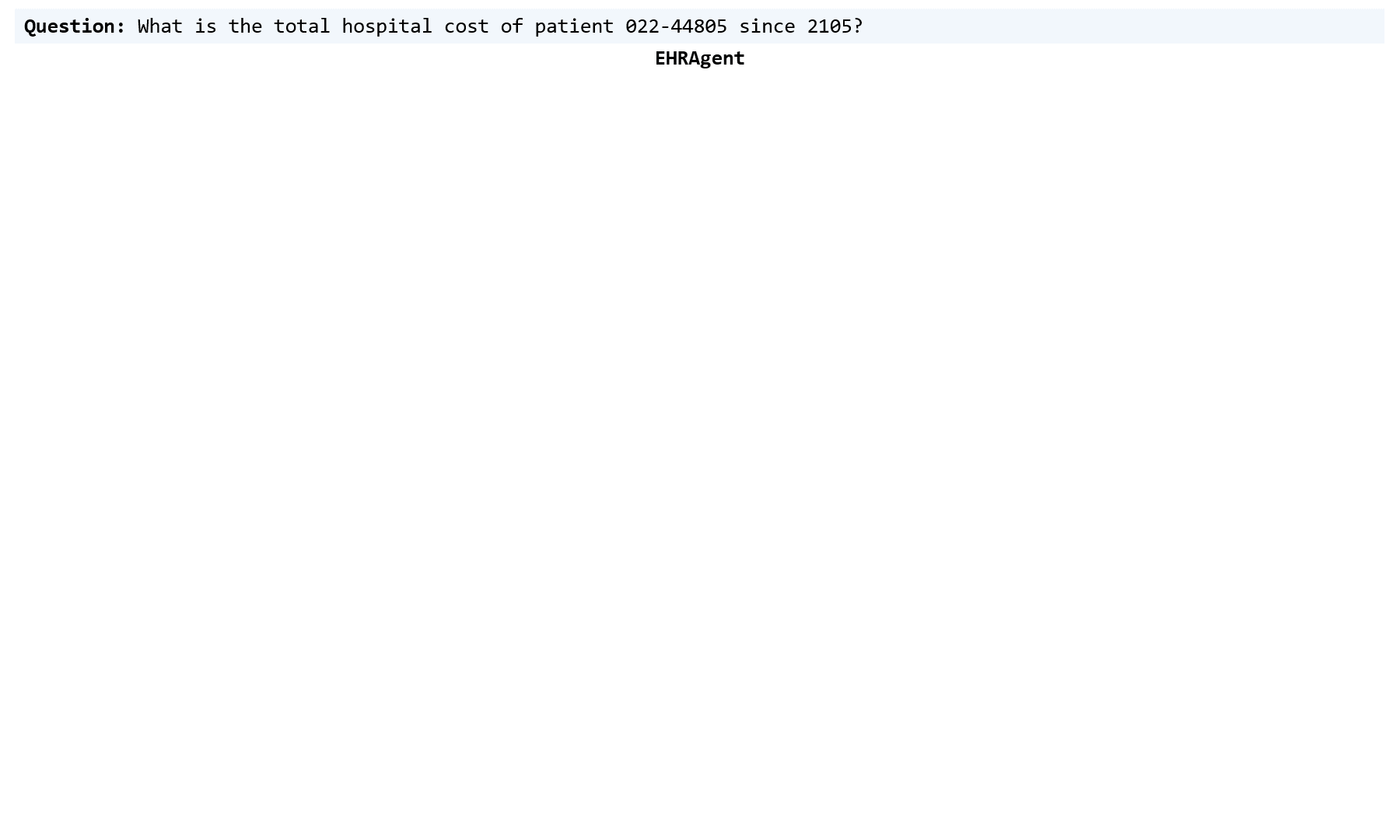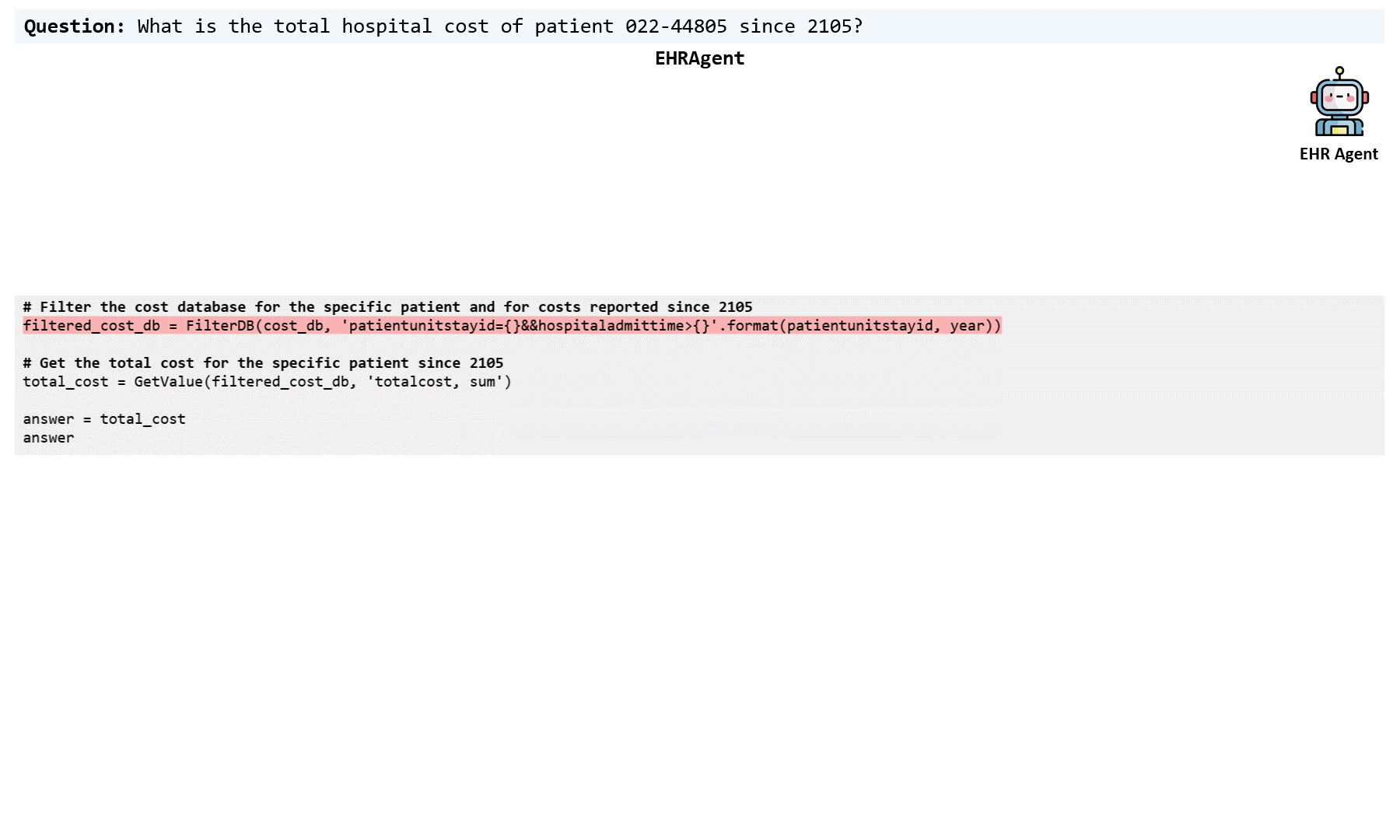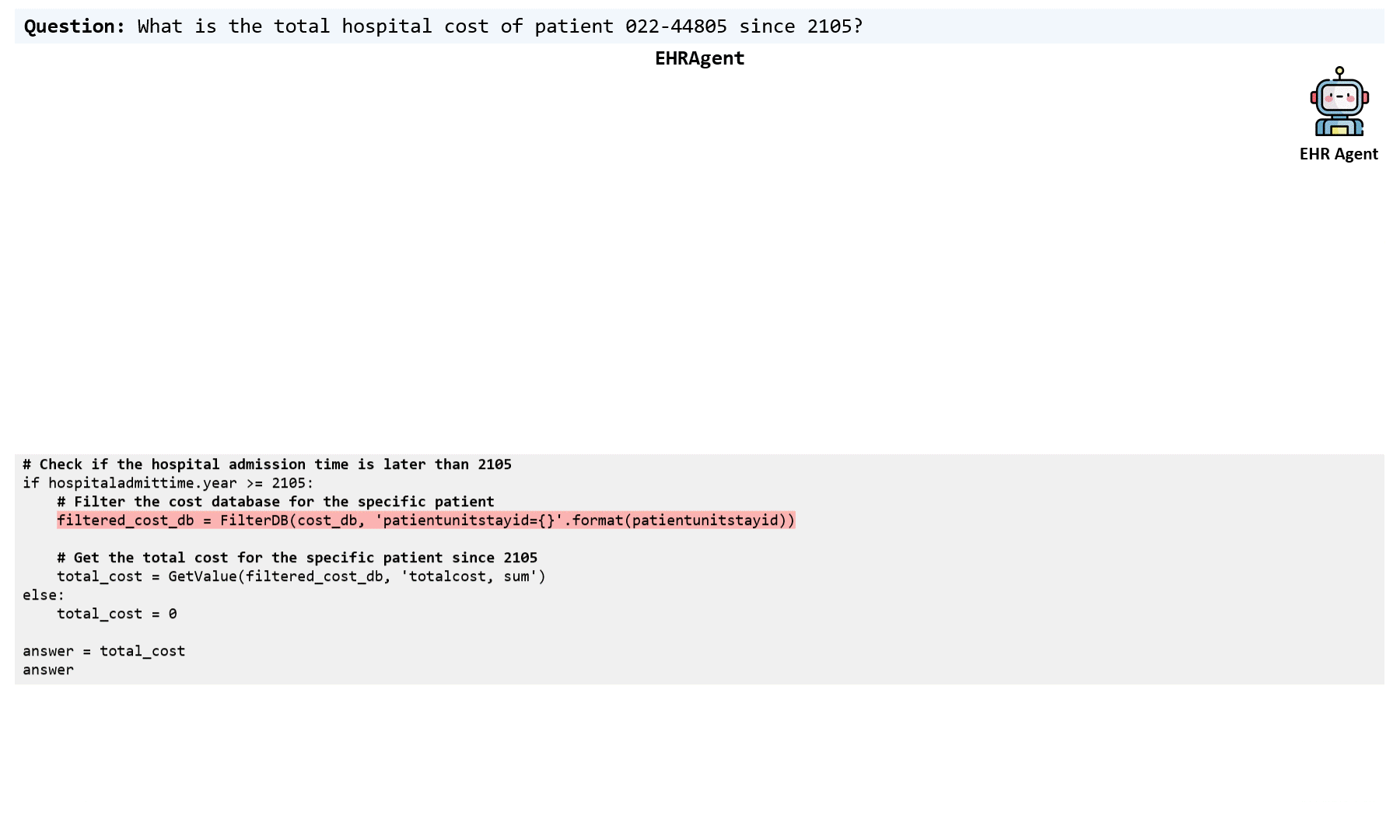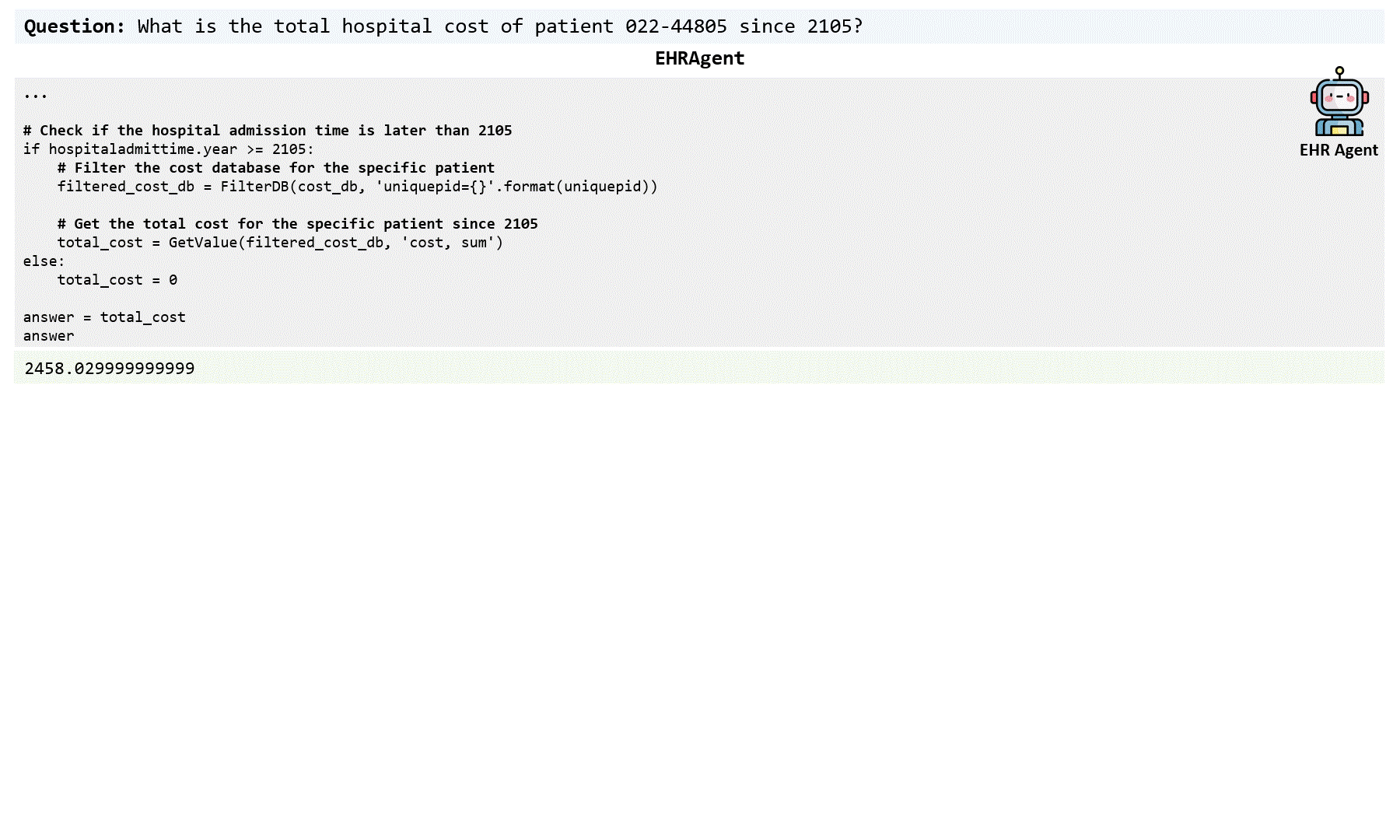
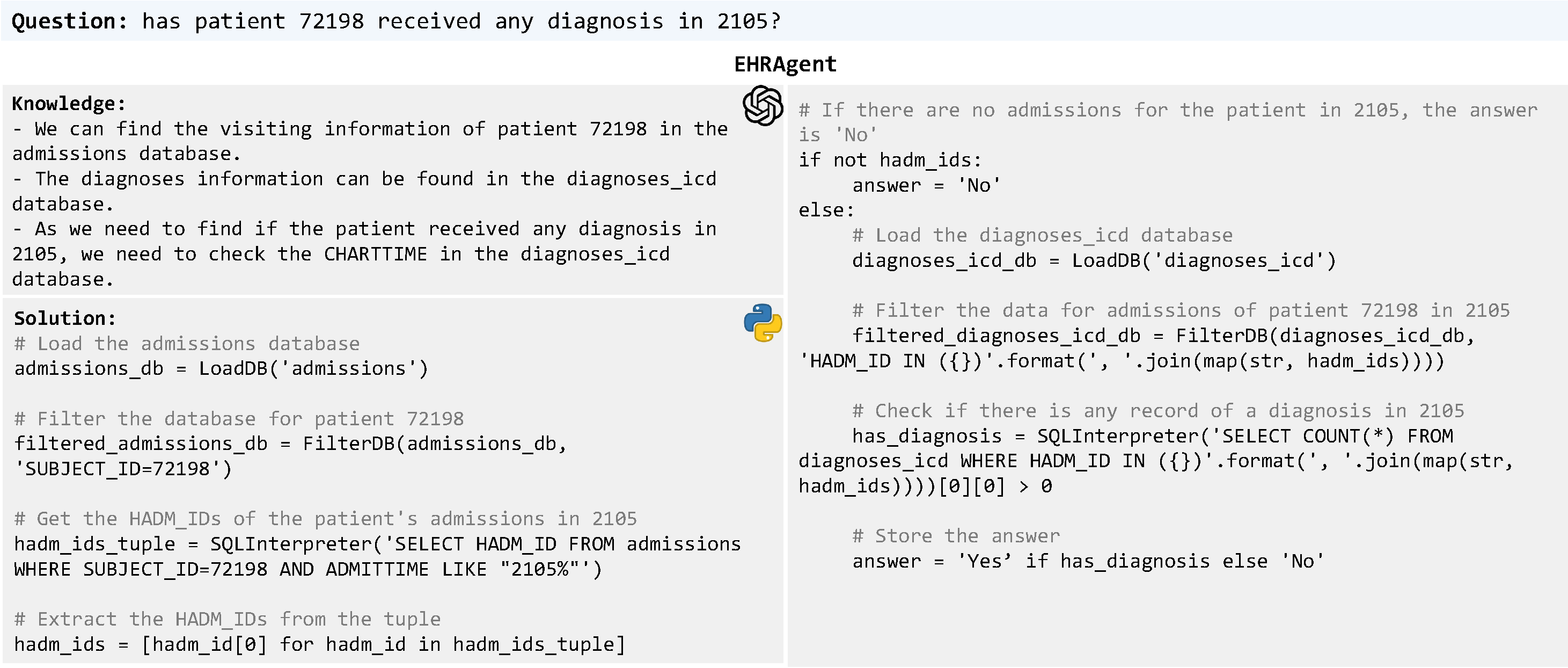
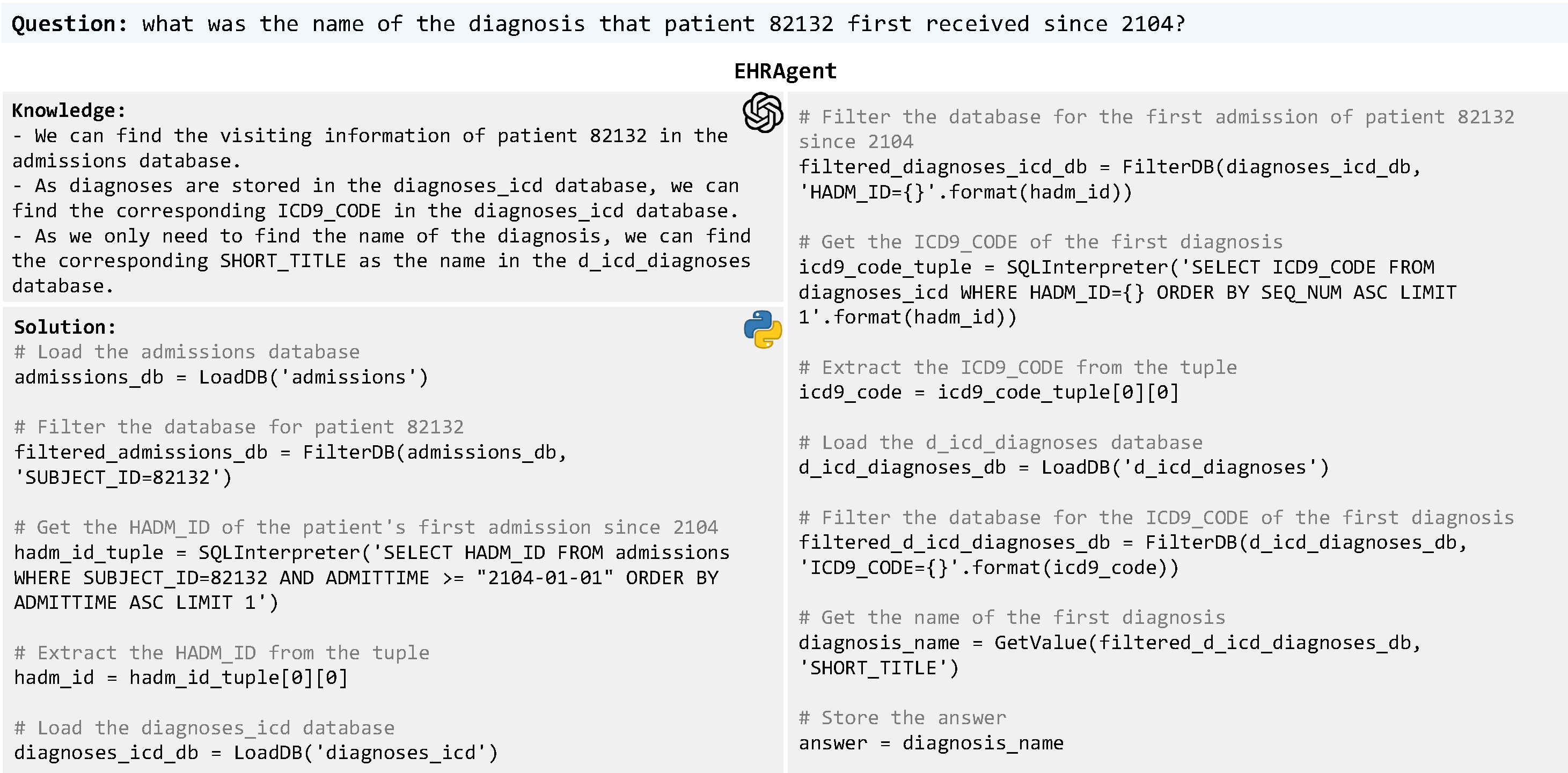
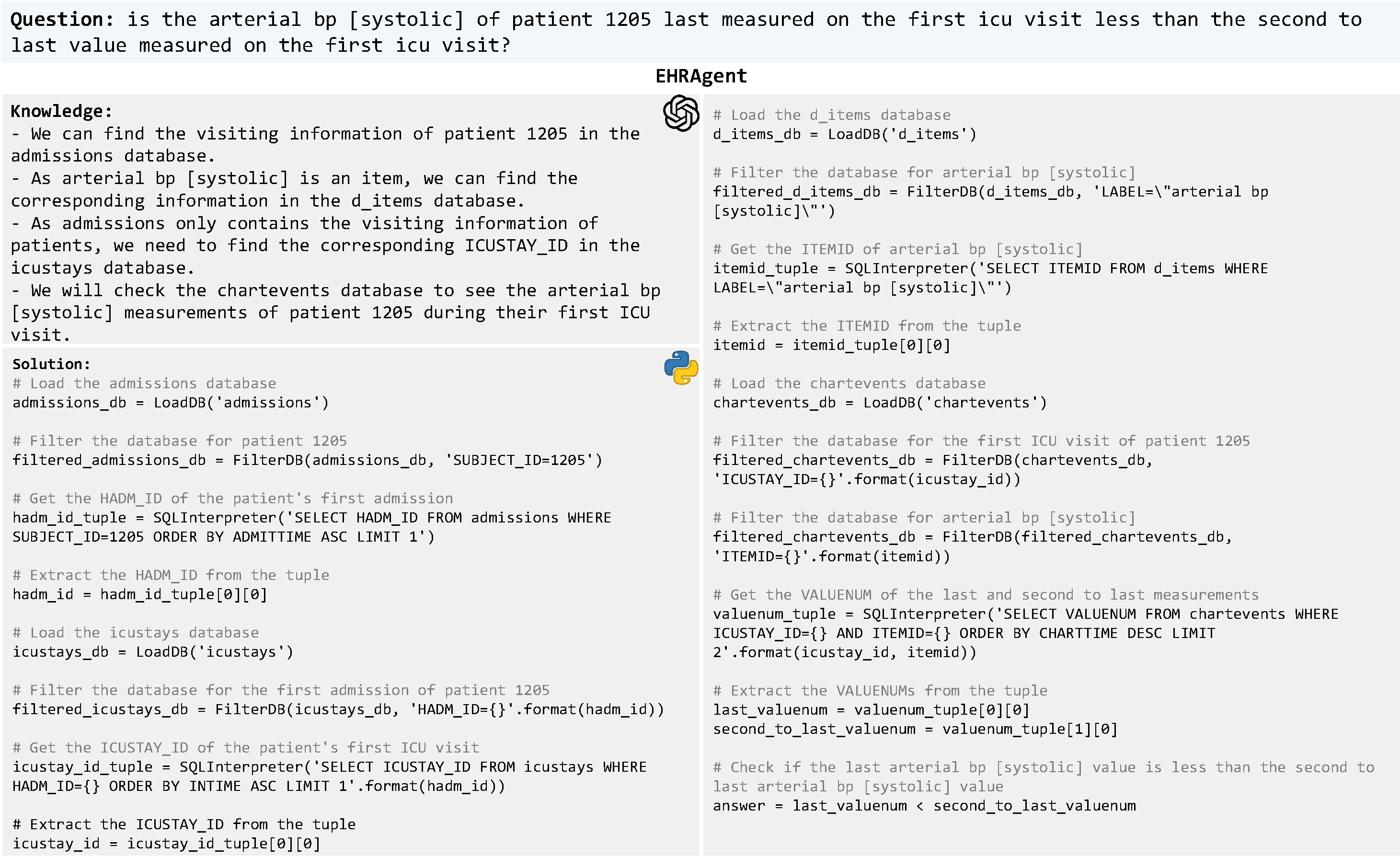
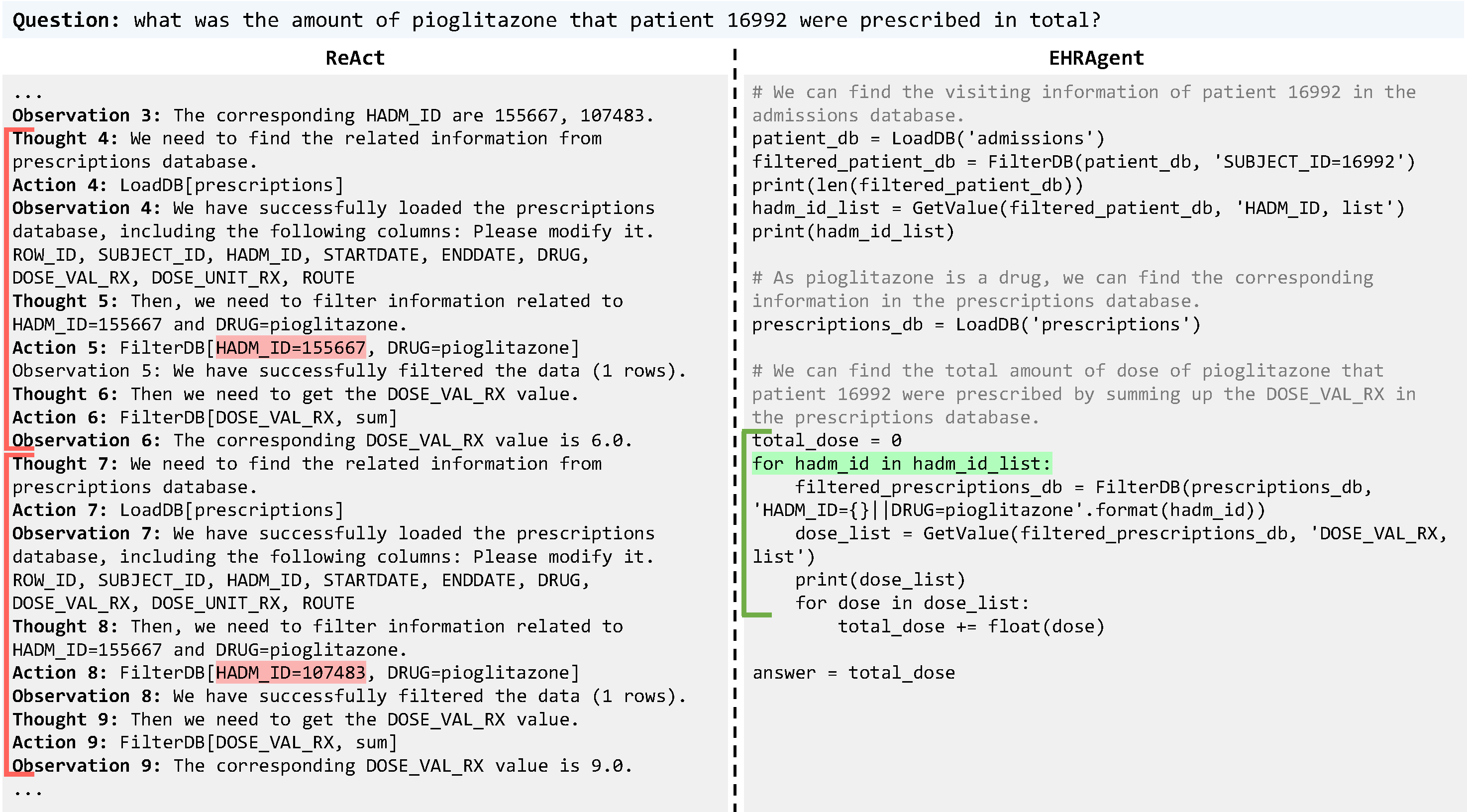
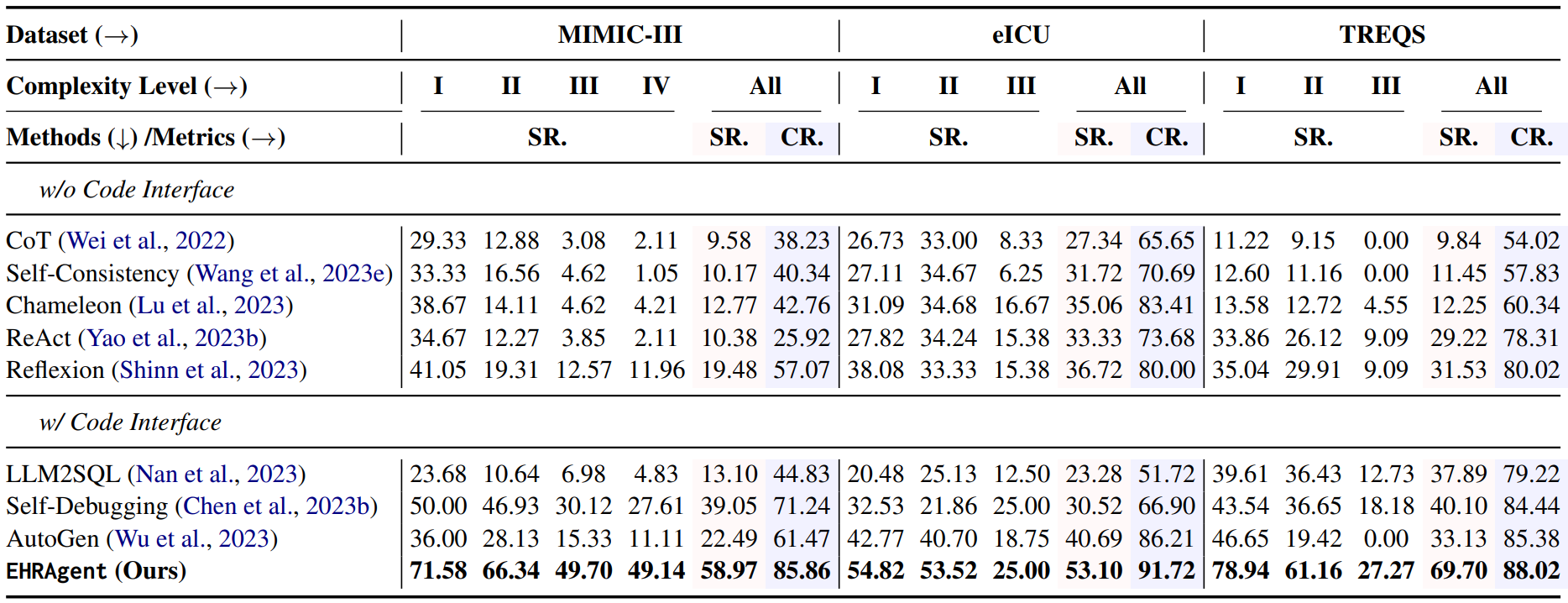
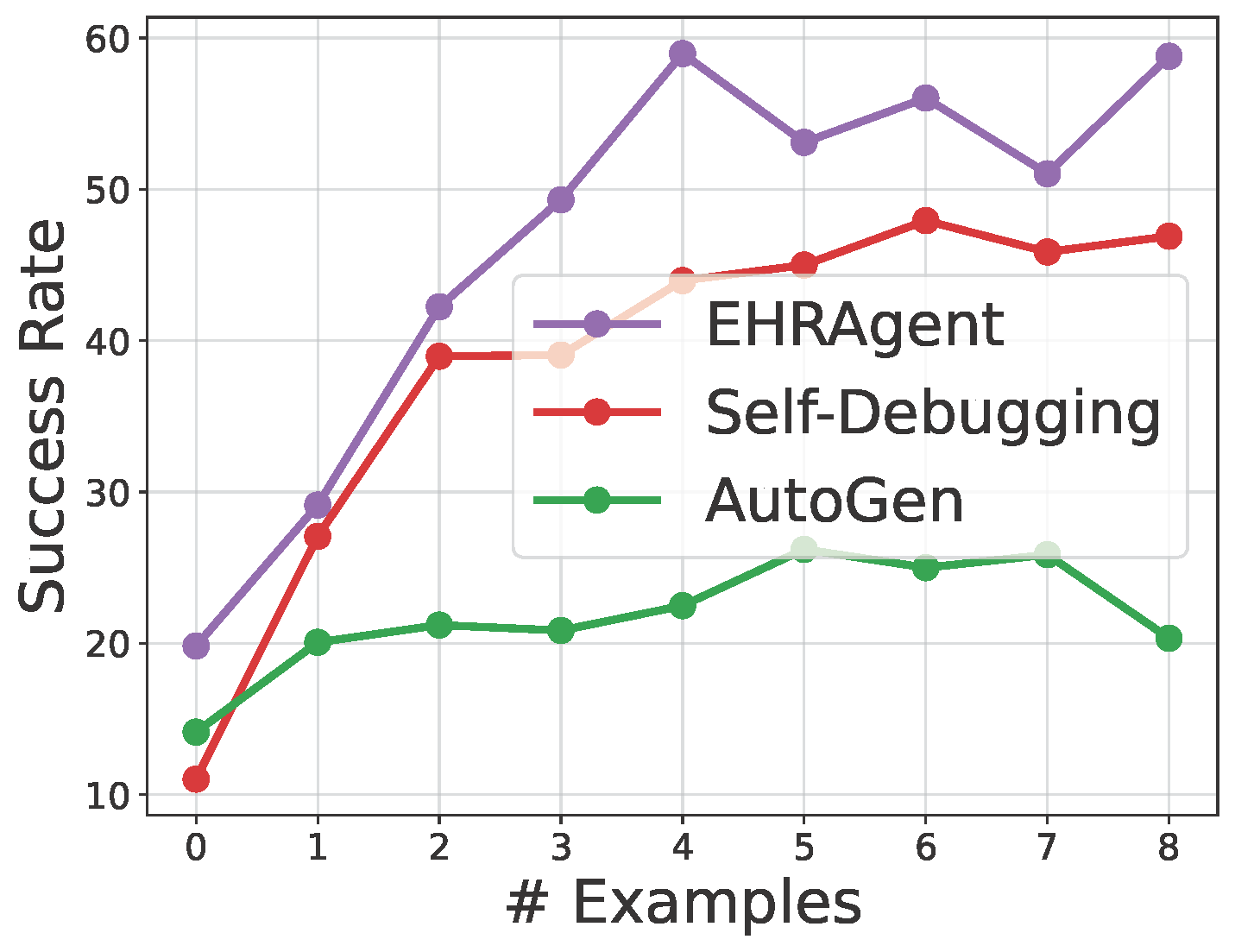
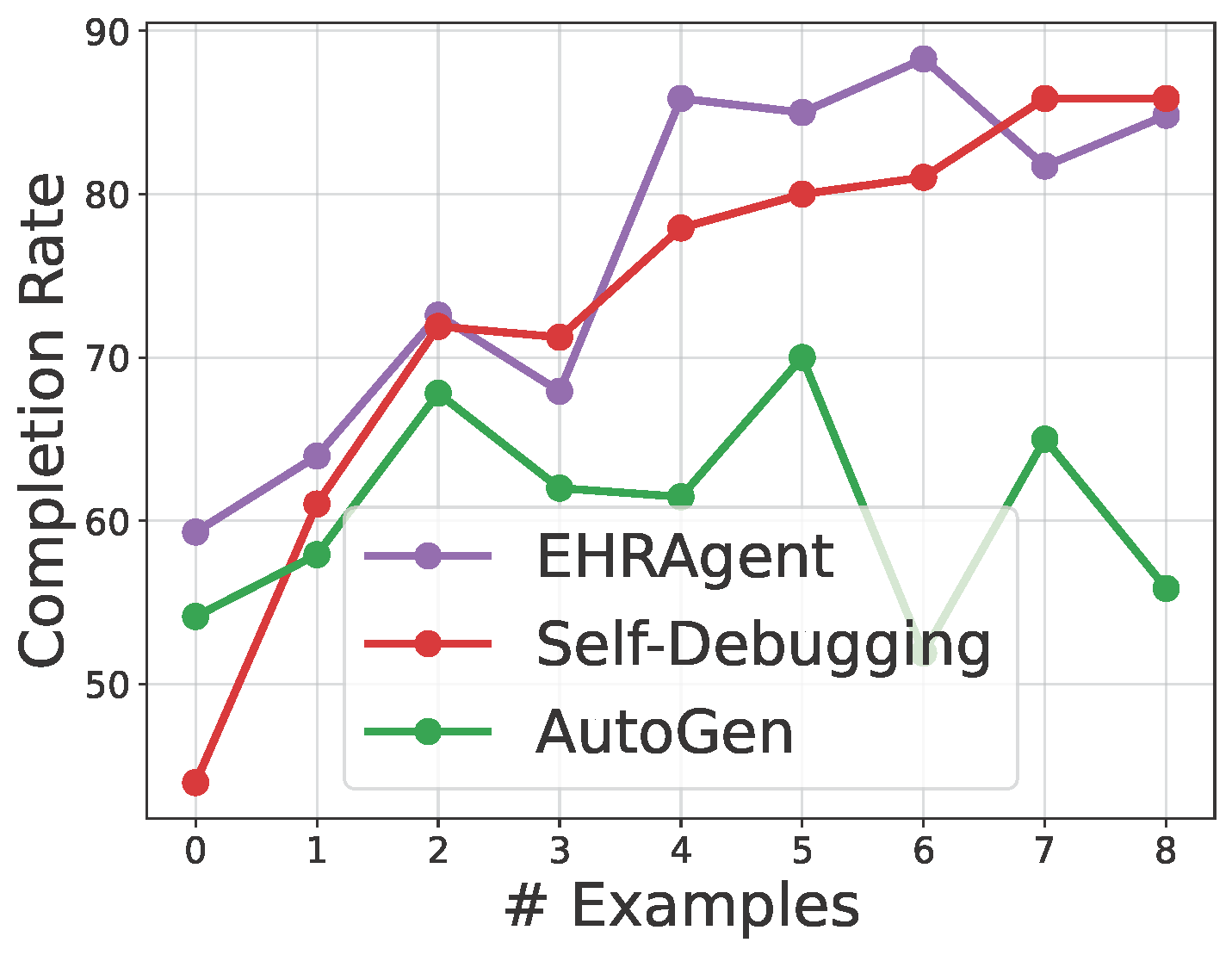
Large language models (LLMs) have demonstrated exceptional capabilities in planning and tool utilization as autonomous agents, but few have been developed for medical problem-solving. We propose EHRAgent, an LLM agent empowered with a code interface, to autonomously generate and execute code for multi-tabular reasoning within electronic health records (EHRs). First, we formulate an EHR question-answering task into a tool-use planning process, efficiently decomposing a complicated task into a sequence of manageable actions. By integrating interactive coding and execution feedback, EHRAgent learns from error messages and improves the originally generated code through iterations. Furthermore, we enhance the LLM agent by incorporating long-term memory, which allows EHRAgent to effectively select and build upon the most relevant successful cases from past experiences. Experiments on three real-world multi-tabular EHR datasets show that EHRAgent outperforms the strongest baseline by up to 29.6% in success rate. EHRAgent leverages the emerging few-shot learning capabilities of LLMs, enabling autonomous code generation and execution to tackle complex clinical tasks with minimal demonstrations.
@misc{shi2024ehragent,
title={EHRAgent: Code Empowers Large Language Models for Complex Tabular Reasoning on Electronic Health Records},
author={Wenqi Shi and Ran Xu and Yuchen Zhuang and Yue Yu and Jieyu Zhang and Hang Wu and Yuanda Zhu and Joyce Ho and Carl Yang and May D. Wang},
year={2024},
eprint={2401.07128},
archivePrefix={arXiv},
primaryClass={cs.CL}
} EHRAgent
EHRAgent